I really like programming things that improve as it runs, but programming self improving code can be a nightmare because the feedback loop tends to be quite large.
Usually when programming something, you click run and within a second or two you know if you need to modify the code, but with these kinds of programs, the code can take hours or days of running before you notice something is off.
The more you need the code to self improve, the longer it needs to run. Self improving code should be saved only for problems where you can’t reasonably code a complete solution. Solving games is complicated, tic tac toe being relatively easy to solve, chess being orders of magnitude harder and go being one of the hardest complete information games. Each new legal move makes the searching of potential moves exponentially more difficult.
“AI” code can help in these scenarios to help trim down the potential moves the code looks at to find great moves. The way this works is you have a neural network that looks at a single game state and have it predict the winner. Loop over all potential moves and pick the move that the neural net likes the best and repeat until the game ends. For training, this doesn’t work because the AI will have tendencies for picking the same series of moves over and over.
The solution is to pick moves based on how unlikely they are and how good they seem. The more a path is taken, force the AI to further avoid that path during training. This should allow a wider search of the game space.
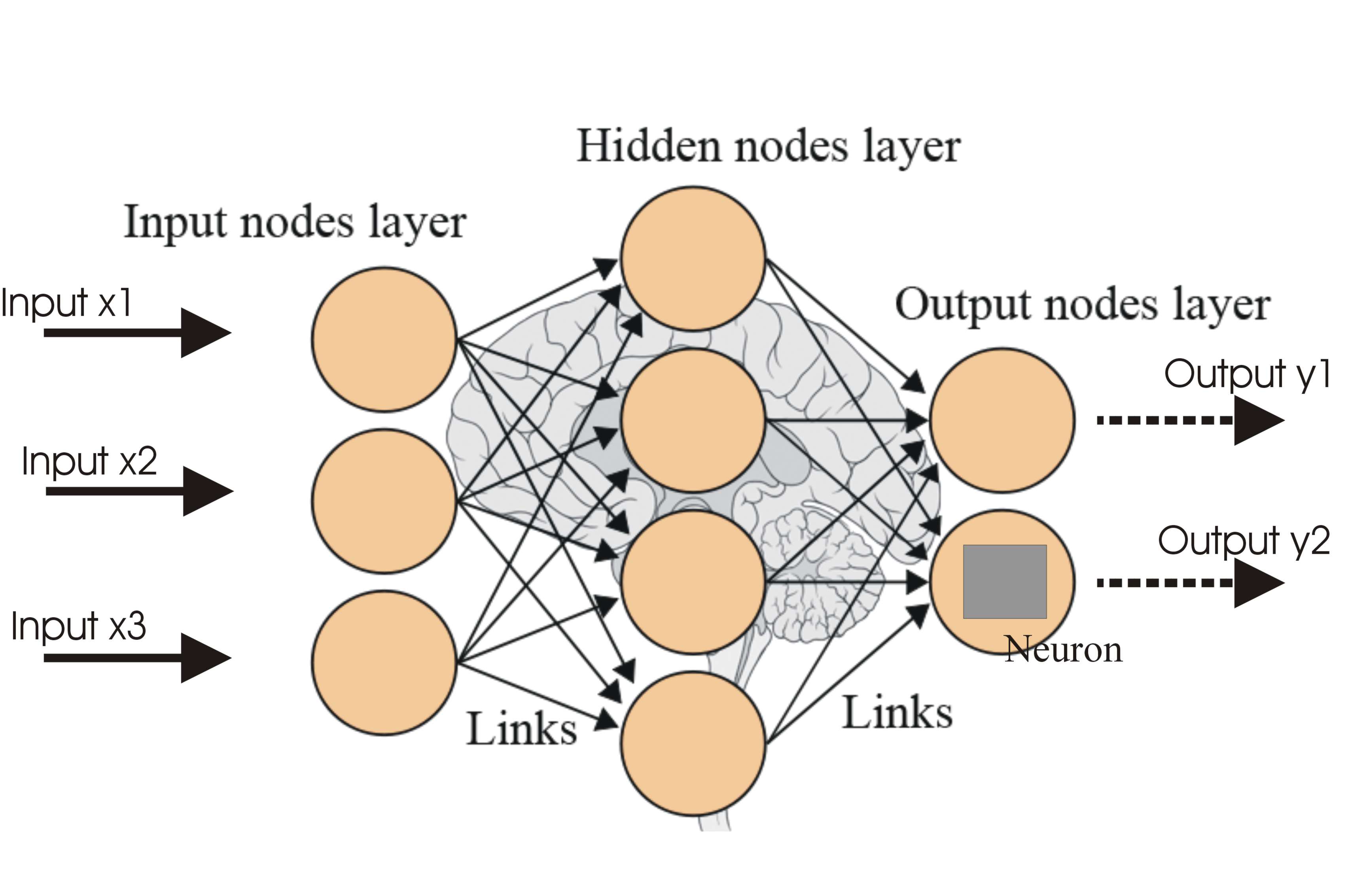
Now, another trick game AI programers can do is to split the training and the exploring into separate processes. The code can store games played into a large list and have half of the computer spend it’s resources updating that list with new games and the other half updating the neural net to better judge the outcomes of those games.
The code I wrote in rust works without that final trick, it just runs one part at a time, but it does keep a list of games played. This makes it easy to change how often it plays vs learns from those games. I also use the neat algorithm, which is not ideal because it’s a trial and error approach instead of a more usual neural net with back propagation.
Feel free to checkout the chess AI trainer which I wrote in rust based on some of the fundamentals found in an alpha go zero cheat sheet I found on the internet somewhere.
Hope you learned something or had fun! I know I did one of those…
🪧 Enjoy Reading This?
Here are some more you might like to read next:
A Tiny Chess Engine
A Delightfully Strong Nemises Jul 29th 2023
Developing a PC + VR game with Godot
A long Journey Jun 1st 2023
My Development Experience With Godot 3 in VR
My Recent Development Shenanigans Aug 16th 2022
💬 Looking for comments?
I don't have comments on this site as they can be time consuming to manage. I'd rather concentrate on programming cool and new things.
Since you can't leave a comment, feel free to ✉️ contact me instead.